Löschung von Äh’s, stottern und Atemgeräuschen mit Cleanvoice
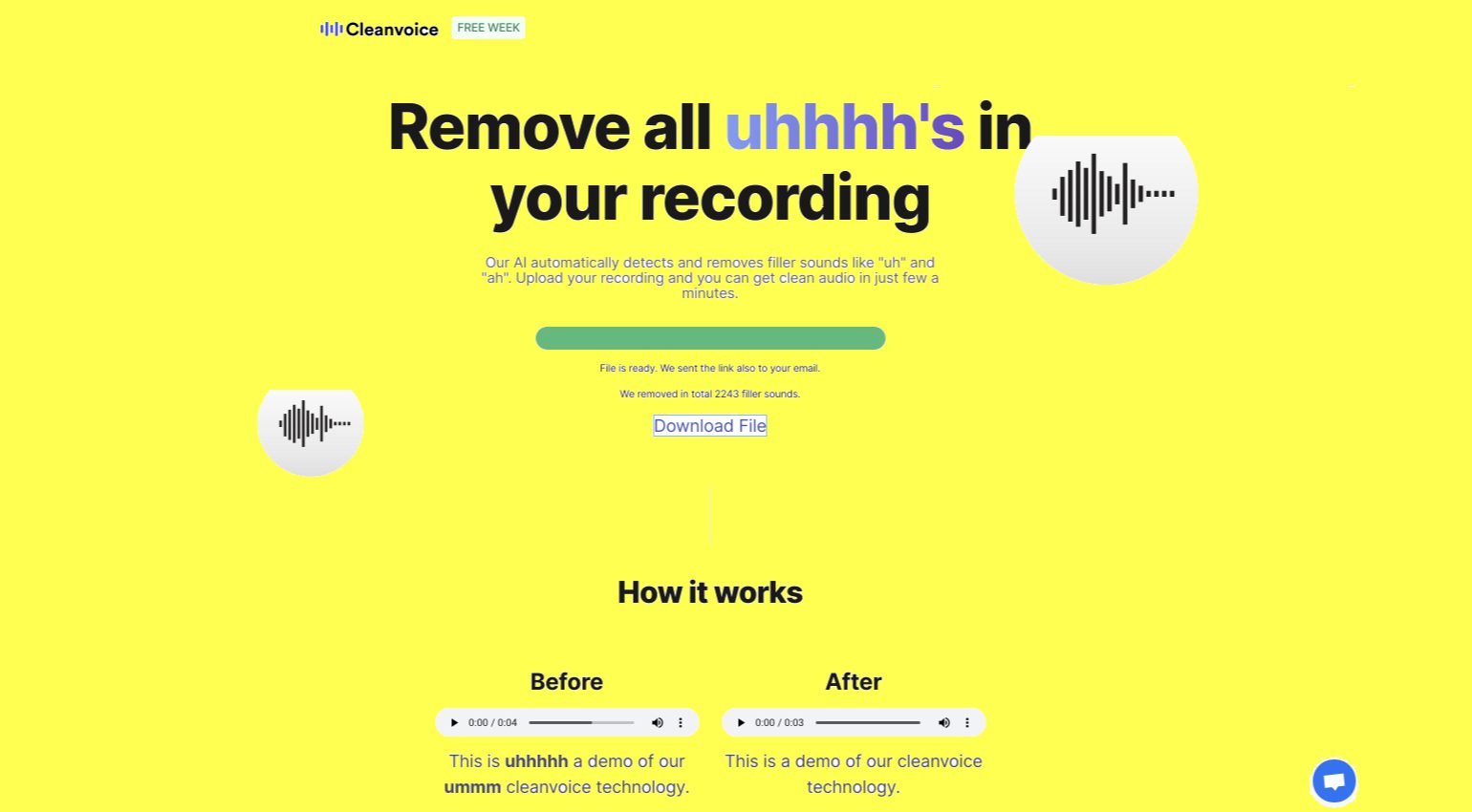

Heute ist eine kostenlose Testwoche bei Cleanvoice. Damit können hochgeladene und sehr lange Audiofiles von störenden Sprecherlauten und unnötigem Stottern befreit werden. Die Berechnung dauert nur wenige Minuten.
Cleanvoice – Die Äh’Lösung
Wenn du Sprecher, Podcaster, Videocaster oder Ersteller von Tutorials bist, kennst du das Problem. Besonders in Live eingesprochenen Texten und freier Rede befinden sich oft zu viele Störgeräusche und „Äh“-Laute durch das sprechende Denken. Das ist anstrengend für deine Hörer. Deshalb gibt es den neuen Webservice von Cleanvoice. Hochgeladen werden können MP3 oder WAV-Dateien. Nach etwa 5-10 Minuten bekommt man bereits die bereinigte und fertige Datei zum Download und wird per E-Mail benachrichtigt.
Beeindruckender Selbsttest
Mit meinem letzten Videocast SequencerTalk habe ich diesen Service testweise auf die fertige Livesendung angewendet. Eine Sendung von knapp 2 Stunden. Die Uploadgrenze ist mit 400 MB sehr großzügig bemessen. Solange eine MP3 reicht, können mehrere Stunden Material verarbeitete werden. Das Ergebnis kann sich hören lassen. Ich fand die komplette Audiodatei wesentlich besser und es fehlte nichts an „Sprachwitz“. Spektakuläre 14 Minuten kürzer ist das errechnete Audiofile, welches allerdings einige Minuten Stille aus der Pre-Show enthielt. Somit handelt es sich nicht vollständig um „Äh“-Material“, was die Berechnung entfernt hat. Das Ergebnis wirkt dennoch nicht beschnitten, mitten in Pausen, im Fluss oder mit Sprachwitz gewürzten Teilen als „zu künstlich“.
Cleanvoice funktioniert auf Deutsch und Englisch und offenbar auch in anderen Sprachen aktuell brauchbar. Ich habe jedoch nur deutsche Sprach-Files geprüft. Die Technik basiert auf Machine Learning und Big-Data-Erkennung durch den Scan einer Vielzahl von Audiofiles (KI). Es werden Mundschmatzen, Äh’s und „Nachdenkgeräusche“ bereits jetzt gut ausgefiltert. Angekündigt sind auch Stotterbereinigung und sogar unsinnige Floskeln und Füllworte „ohne Sinn“ sollen in Zukunft erkannt werden. Im Text steht dazu „I think, I mean …“, also „ich denke…“, was in einigen US-Podcasts wirklich sehr oft zu hören ist. Ebenso sind Mehrspuraufnahmen für Mitte Juli vorgesehen.
Videosynchronität
Da das Audiofile nicht nur von „Äh’s“ befreit, sondern auch verkürzt wird, lässt sich das Ergebnis nicht auf Videosendungen anwenden, denn die Synchronität würde verloren gehen. Es soll aber eine zeitsouveräne Timestamp-Version geben, die aktuell in der Betaversion vorliegt. Dann könnten die Audiodateien wieder unterlegt werden.
Diese konnte ich aber nicht prüfen. Es wäre der größte Wunsch, Videoversionen mit gleich langen Varianten zu versorgen, die lediglich unschöne Geräusche und „Äh’s“ ausblendet, denn dann würden auch „Youtuber“ davon profitieren können. Die Qualität der Bearbeitungen ist nämlich ist hervorragend. Vermutlich ist das schwerer, da Restgeräusche des Hintergrundes nicht entfernt werden sollten, da sonst die Störwirkung eher wieder vergrößert werden müsste.
Mehr über Cleanvoice
Der Service wird als Festpreis und Monatsabo angeboten werden und bietet dann per Code einen Zugang für eine bestimmte Anzahl von Wandlungen in einem bestimmten Zeitraum. Nach diesen werden die Preise gestaltet. Aktuell gibt es noch keine Preise, da der Service neu ist. Der Service wird aktuell auch ständig verbessert. Es kommen auch weitere Funktionen hinzu.
Wer noch ein paar Hintergründe in einem Podcast hören möchte, kann sich dazu eine Viertausend Hertz Folge anhören.
10 Antworten zu “Löschung von Äh’s, stottern und Atemgeräuschen mit Cleanvoice”
..praktisch fürs nächste Boris Becker Interview…
ich bezweifele stark, dass es an iZotope RX ran kommt. In deren Demo sind die umm und uhh ja teils noch drin.
Hast du es mal mit „realistischem“ Material ausprobiert – ich habe das gemacht und es klappt gut, es ist jedenfalls deutlich besser. Nicht alles, aber sehr vieles. Es ist auch nicht „unnatürlich“. Deshalb ist es offenbar brauchbar und gerade erst neu – es wird wohl verbessert werden, auf deren Site ist der Plan was wann passieren soll.
Soweit ich weiss, kann Isotope nur Vocals hervorheben und Geräusche wie Vogelzwitschern entfernen – nicht aber Äh’s und eigene Atemgeräusche, die genau das sind, was live entsteht und auch nervt – das macht I. nicht schlechter – aber das ist meiner Ansicht das große Ding hier – wäre es zeitsouverän würde ich es nachträglich auf Videoton ansetzen („Laberpodcast“)
Da werde ich mal die Tonspur von „Voll Normal“ durchjagen :)
Das würde ich mir als Handyapp beim Telefonieren wünschen, aber dann hätte mein Schwiegervater gar nichts mehr zu sagen :D
Gleich mal ausprobiert, das könnte mich einen Teil meines Jobs kosten :D Ist aber tatsächlich noch nicht wirklich gut nutzbar. Ich würde mich nicht darauf verlassen, dass das Ergebnis natürlich klingt. Man fällt sich immer wieder selbst ins Wort und der natürliche Redefluss ist nicht mehr gegeben, deutlich hektischer. Das könnte ich mir nicht lange anhören. Ist aber erschreckend, was schon möglich ist.
Probier es bitte mal aus – jetzt wo es noch kostenlos ist und sag deine ehrliche Meinung anhand eines Podcastes oder eines Sprecherbeitrages eines Non-Pro-Sprechers zB Radiogast oder eben in Gesprächsrunden. Eine andere Meinung ist da interessant mit anderem Material. Freu mich über Feedback.
Gut unser SequencerTalk ist ja nun extra live und ungeschnitten. Da Hilft dann doch nur Sprachtraining. Aber völlig verrückt was mittlerweile machbar ist. Ich habe für den letzten Exploding Shed Livestream einen Shortcut gemacht wo ich fast eine Stunde an Material händisch gekürzt habe, da wäre sowas für komplette Videos echt toll gewesen.
Deshalb fand ich ihn auch als perfekten Test für das Tool – ich würde es als Neu-Upload nutzen, wenn es in der Länge gleich bliebe. Ist viel angenehmer – dann. Per Hand ist das nicht zu schaffen – für 2,5h Material in der Woche. Dh – schon – aber dann fehlt sie für andere Dinge.
Für Exploding Shed würde es sich lohnen, so es denn im Video keine zeitlichen Veränderungen bringen würde. Denke aber, die möchten anbieten, dass der Podcast insgesamt kürzer ist und Atempausen kürzer sein können – das wäre auch für einen Player sehr gut. Aber das mit dem Videosync wäre meine Wunschvorstellung – ich würde das Tool dann beschicken und die Nachgucker hätten mehr Freude.
Sie sehen gerade einen Platzhalterinhalt von Facebook. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr InformationenSie sehen gerade einen Platzhalterinhalt von Instagram. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr InformationenSie sehen gerade einen Platzhalterinhalt von X. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr Informationen